
Wenn Teams Git adaptieren wollen, ist es oft problematisch, den richtigen Einstieg für die Implementierung zu finden. Dabei ist der Umstieg von Teams, die von Subversion migrieren, denkbar einfach: Sie können mit Git nach demselben zentralisierten Workflow wie mit SVN arbeiten.
Der zentralisierte Workflow
Die Transition zu einer verteilten Versionskontrolle wird häufig als große Herausforderung angesehen. Dabei muss ein Entwicklungsteam seinen bestehenden Workflow gar nicht aufgeben, um sich Git zunutze zu machen. Vielmehr kann es Projekte auf exakt dieselbe Weise wie mit Subversion entwickeln.
Git bietet gegenüber SVN allerdings einige große Vorteile. Zunächst hat jeder Entwickler seine eigene lokale Kopie des gesamten Projekts. In dieser isolierten Umgebung arbeiten alle Entwickler unabhängig von allen anderen Änderungen am Projekt – sie können ihrer lokalen Repository Commits hinzufügen und die Upstream-Entwicklung komplett ignorieren, bis zum Beispiel das Feature fertig ist, mit dem sie sich gerade beschäftigen.
Zweitens bietet Git ein ausgereiftes Branching- und Merging-Modell. Anders als bei SVN bringen Git-Workflows ausgereifte Sicherheitsmechanismen für die Integration von Code und das Teilen von Änderungen zwischen Repositories mit.
So funktioniert es
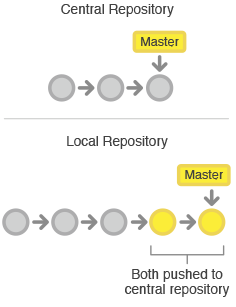
Wie Subversion nutzt der zentralisierte Git-Workflow eine zentrale Repository als Einstiegspunkt für alle Änderungen am Projekt. Statt trunk heißt der Entwicklungs-Branch Master, und alle Änderungen werden in diesen Branch commitet. Dieser Workflow erfordert keine anderen Branches neben dem Master.
Entwickler starten, indem sie die zentrale Repository klonen. In ihren eigenen lokalen Kopien des Projekts editieren sie Dateien und committen Änderungen, wie sie es mit SVN tun würden. Allerdings werden neue Commits lokal gespeichert – sie sind vollständig von der zentralen Repository isoliert. So kann der Entwickler die Synchronisierung Richtung Upstream aufschieben, bis er einen geeigneten Break-Point erreicht hat.
Um Änderungen ins offizielle Projekt auszuliefern, “pusht” der Entwickler seinen lokalen Master-Branch in die zentrale Repository. Dies ist das Äquivalent zu svn commit, abgesehen davon, dass all jene lokalen Commits hinzugefügt werden, die nicht bereits im zentralen Master-Branch sind.
Konflikte handhaben
Die zentrale Repository repräsentiert das offizielle Projekt, ihre Commit-History sollte also als unantastbar und unveränderlich gelten. Wenn die lokalen Commits eines Entwicklers von der zentralen Repository abweichen, verweigert Git das Pushen dieser Änderungen, da sie offizielle Commits überschreiben würden.
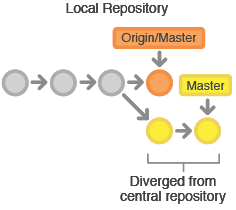
Bevor der Entwickler sein Feature veröffentlichen kann, muss er die aktualisierten zentralen Commits zu sich holen und per Rebasing seine eigenen Änderungen auf diese aufsetzen. Er fügt seine Änderungen also dem hinzu, was alle anderen bereits getan haben. Das Ergebnis ist eine durch und durch lineare History wie bei traditionellen SVN-Workflows.
Wenn lokale Änderungen in direktem Konflikt mit Upstream-Commits stehen, pausiert Git den Rebasing-Prozess und bietet die Möglichkeit, die Konflikte manuell zu lösen. Das Gute an Git ist, dass es mit git status und git add für das Generieren von Commits und für die Auflösung von Merge-Konflikten dieselben Befehle nutzt.
Das macht es neuen Entwicklern einfach, ihre eigenen Merges zu handhaben. Und falls größere Probleme auftreten, ist es jederzeit möglich, das gesamte Rebasing abzubrechen und es neu zu versuchen.
Fazit
Es ist also möglich, den traditionellen Subversion-Entwicklungs-Workflow mit einigen wenigen Git-Befehlen zu replizieren. Das ist gut für Teams, die von SVN umsteigen, macht sich die verteilte Natur von Git aber nicht zunutze. Wenn das Team einmal mit dem zentralisierten Workflow vertraut ist, sollte es sich definitiv mit den weiteren Vorteilen von Git als verteilter Versionskontrolle beschäftigen.
Beispiel
Nun zeigen wir, wie ein exemplarisches kleines Team mithilfe dieses Workflows zusammenarbeitet: Entwickler A und Entwickler B können an verschiedenen Features arbeiten und ihre Beiträge via zentralisierter Repository teilen.
Zentrale Repository aufsetzen

Zunächst muss die zentrale Repository auf einem Server angelegt werden. Für ein neues Projekt kann eine leere Repository initialisiert werden, andernfalls muss eine bestehende Git- oder SVN-Repository importiert werden:
ssh user@hostgit init --bare /path/to/repo.git
Dabei muss user ein valider SSH-Nutzername sein, host ist die Domain oder IP-Adresse des Servers,/path/to/repo.git zeigt den Ort an, an dem die Repository gespeichert werden soll. Die Erweiterung .git wird dem Repository-Namen standardmäßig angefügt, um zu indizieren, dass es sich um eine leere Repo handelt.
Jeder klont die zentrale Repository

Als nächstes erzeugt jeder Entwickler eine lokale Kopie des kompletten Projekts. Das erfolgt mit dem Git-Befehl git clone:
git clone ssh://user@host/path/to/repo.git
Wird eine Repository geklont, fügt Git automatisch einen Shortcut namens origin hinzu, der auf die Ursprungs-Repository zurückverweist, um künftig mit dieser interagieren zu können.
Entwickler A arbeitet an seinem Feature
In seiner lokalen Repository kann Entwickler A nach dem Standard-Commit-Prozess von Git an seinen Feautures arbeiten: Edit, Stage, Commit. Der Staging-Bereich bietet eine Möglichkeit, einen Commit vorzubereiten, ohne der Working Directory jede Änderung hinzufügen zu müssen. So lassen sich höchst fokussierte Commits erzeugen, selbst wenn viele lokale Änderungen vorgenommen wurden.
git status # State der Repo anzeigengit add # Datei stagengit commit # Datei committen
Da dieses Befehle lokale Commits erzeugen, kann Entwickler A sie so oft ausführen, wie er möchte, ohne sich Sorgen machen zu müssen, was in der zentralen Repository passiert. Das kann bei großen Features sehr nützlich sein, die in kleinere Bestandteile zerlegt werden müssen.
Entwickler B arbeitet an seinem Feature
In der Zwischenzeit arbeitet Entwickler B in seiner eigenen lokalen Repository an seinem Feature – ebenfalls nach dem Edit/Stage/Commit-Prozess. Er muss sich ebenfalls nicht darum kümmern, was in der zentralen Repository los ist, und er muss sich auch nicht darum kümmern, was in der Repo von Entwickler A vor sich geht, denn alle lokalen Repositories sind privat.
Entwickler A veröffentlicht sein Feature
Wenn Entwickler A sein Feature fertig hat, wird er seine lokalen Commits der zentralen Repository hinzufügen wollen, damit andere Teammitglieder darauf zugreifen können. Dies erfolgt mit dem Befehlgit push:
git push origin master
Wie gesagt, ist origin die Remote-Verbindung zur zentralen Repository, die Git erstellt hat, als Entwickler A die Repo geklont hat. Das Argument master weist Git an, dass der origin-Master-Branch wie der lokale Master-Branch aussehen soll. Da die zentrale Repository bislang nicht aktualisiert wurde, wird es hier keine Konflikte geben und der Push wird wie gewünscht erfolgen.
Entwickler B versucht, sein Feature zu veröffentlichen
Nachdem Entwickler A sein Feature gepusht hat, möchte das auch Entwickler B tun. Er nutzt denselben Befehl:
git push origin master
Doch da die lokale History inzwischen von der zentralen Repository abweicht, wird Git die Aufforderung verweigern und eine Fehlermeldung ausgeben, die Entwickler B daran hindert, offizielle Commits zu überschreiben:
error: failed to push some refs to '/path/to/repo.git'hint: Updates were rejected because the tip of your current branch is behindhint: its remote counterpart. Merge the remote changes (e.g. 'git pull')hint: before pushing again.hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Er muss die Aktualisierungen von Entwickler A in seine eigene Repository ziehen, diese mit seinen eigenen lokalen Änderungen integrieren und es erneut versuchen.
Rebasing auf den Commits von Entwickler A
Entwickler B kann den Befehl git pull nutzen, um Upstream-Änderungen in seine Repository einzubinden. Dieses Kommando funktioniert ähnlich wie svn update – es zieht die gesamte Upstream-Commit-History in die lokale Repository von Entwickler B und versucht, diese mit seinen lokalen Commits zu integrieren:
git pull --rebase origin master
Die Option --rebase sagt Git, dass alle Commits von Entwickler B zuoberst auf den Master-Branch aufgesetzt werden sollen, nachdem die Synchronisierung mit den Änderungen aus der zentralen Repository erfolgt ist.
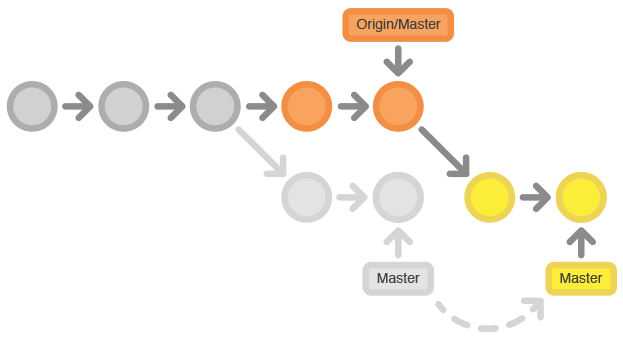
Der Pull würde auch funktionieren, wenn B diese Option vergessen hätte, aber das würde immer dann, wenn jemand einen Synchronisation mit der zentralen Repository herbeiführen will, zu einem überflüssigen Merge Commit führen. Für diesen Workflow ist rebase immer besser als das Generieren eines Merge Commits.
Entwickler B löst einen Merge-Konflikt auf
Das Rebasing funktioniert, indem ein lokaler Commit nach dem anderen in den aktualisierten Master-Branch transferiert wird. Das bedeutet, dass sich Merge-Konflikten viel leichter auf die Spur kommen lässt – im Gegensatz zu einem massiven Merge Commit.
Dadurch sind die Commits so fokussiert wie möglich und ist für eine saubere Projekt-Historie gesorgt. Zugleich ist es deutlich einfacher herauszufinden, wo Bugs eingeführt wurden, und Änderungen – falls nötig – zurückzurollen, ohne dass sich dies großartig auf das Projekt auswirkt.
Wenn A und B an Features arbeiten, die unabhängig voneinander sind, ist es unwahrscheinlich, dass der Rebasing-Prozess zu Konflikten führt. Falls aber doch, pausiert Git das Rebasing beim aktuellen Commit und gibt eine Fehlermeldung und entsprechende Anweisungen aus:
CONFLICT (content): Merge conflict in <some-file>

Ein großer Vorteil von Git besteht darin, dass jeder seine eigenen Merge-Konflikte selbst auflösen kann. In diesem Beispiel würde Entwickler B den Befehl git status ausführen, um zu sehen, wo das Problem liegt. Dateien, die Konflikte ausgelöst haben, erscheinen in der Sektion Unmerged paths.
# Unmerged paths:# (use "git reset HEAD <some-file>..." to unstage)# (use "git add/rm <some-file>..." as appropriate to mark resolution)## both modified: <some-file>>
Dann kann B die entsprechenden Dateien weiter bearbeiten, diese wie üblich stagen und mit git rebase integrieren:
git add <some-file> git rebase --continue </some-file>
Ist alles okay, macht Git mit dem nächsten Commit weiter und wiederholt diesen Prozess bei allen weiteren Commits, die Konflikte verursachen.
Und falls sich die Auflösung von Konflikten problematischer als gedacht gestaltet, kann das Rebasing mit dem folgenden Kommando abgebrochen werden:
git rebase --abort
Der Zustand vor der initialen Ausführung des Rebasings wird wieder hergestellt.
Entwickler B veröffentlicht sein Feature
Nach der Synchronisation mit der zentralen Repository ist Entwickler B in der Lage, seine Änderungen erfolgreich zu veröffentlichen:
git push origin master